Umfangreiche, qualitativ hochwertige und strukturierte Gesundheitsdaten eröffnen enorme Chancen für das Gesundheitswesen: Etwa für datengetriebene medizinische Forschung, Public Health Surveillance oder die Entwicklung innovativer KI-Lösungen, die medizinisches Fachpersonal bspw. bei der Diagnostik, Datenanalyse und Dokumentation unterstützen.
Seit 2019 betreibt Tiplu Deutschlands größtes medizinisches Machine Learning-Netzwerk mit mehr als 130 Partnerkliniken. Über dieses stehen mehr als 10 Mio. med. anonymisierte, interoperable Patientenakten zur Verfügung – und damit das gesammelte Wissen zahlreicher Fallkonstellationen sämtlicher Fachdisziplinen. Tiplu setzt seit seiner Gründung konsequent auf Künstliche Intelligenz als praxisrelevante Technologie und gehört zu den wenigen Unternehmen im deutschsprachigen Raum, die ML-Modelle nicht nur anwenden, sondern auf Grundlage des ML-Netzes selbst entwickeln, trainieren und einsetzen.
In einer gemeinsam mit der Klinik für Hals-Nasen-Ohren-Heilkunde, Kopf- und Hals-Chirurgie der Universität Witten/Herdecke, St.-Josefs-Hospital Hagen durchgeführten Studie unter der Leitung von Dr. Sabine Eichhorn und Prof. Jonas Park konnte nun die Repräsentativität der Daten im ML-Netz belegt werden.
KI-Lösungen mit valider Datenbasis
Das Paper liefert den wissenschaftlichen Beweis für die hohe Qualität des Tiplu ML-Netzes: Mit einer Stichprobe von über 8 Millionen Behandlungsfällen aus rund 130 Kliniken wurde nachgewiesen, dass die Datenbasis nahezu vollständig mit den offiziellen Daten des Statistischen Bundesamtes korreliert. Tiplus ML-Netz ist nicht mehr nur eine “proprietäre Datenbank”, sondern eine wissenschaftlich validierte Repräsentanz der deutschen Versorgungsrealität.
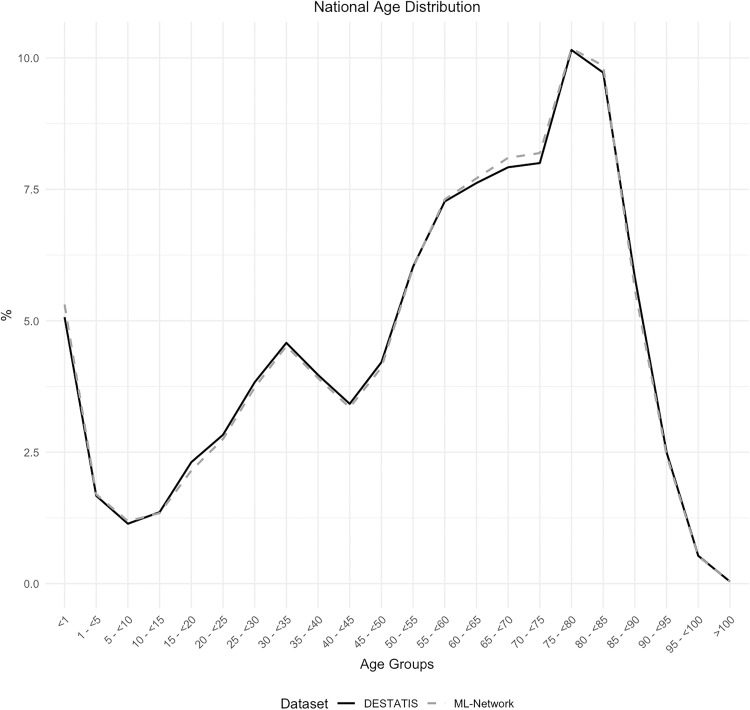
Abb.: Nationale Altersverteilung
Unsere Tiplu-Lösungen basieren somit auf einer Datenbasis, die die echte Versorgungsrealität in Deutschland abbildet, von der Uniklinik bis zum Grundversorger. Das ist die Grundlage für evidenzbasierte Algorithmen für die Patientenversorgung. Unsere ML-Modelle kommen u.a. in der Kode-Detektion mit der Kodiersoftware MOMO sowie der Risikoprädiktion mit der Clinical Decision Support-Software MAIA zum Einsatz.
Studienmethodik und Ergebnisse
Im Rahmen der Studie wurden Basisdaten aus dem ML-Netzwerk mit öffentlich zugänglichen Daten des Statistischen Bundesamtes (DESTATIS) verglichen, um die wissenschaftliche Validität und deutschlandweite Repräsentativität für zukünftige epidemiologische Analysen zu prüfen.
In einer retrospektiven epidemiologischen Sekundäranalyse wurden rund 8 Millionen Falldaten aus dem ML-Netzwerk untersucht und hinsichtlich Alter, Geschlecht, Verweildauer im Krankenhaus, ICD-10-Diagnosen und OPS-Codes mit DESTATIS-Daten verglichen. Zusätzlich wurden ICD-10-Kodes zu Substanzmissbrauch sowie die regionale Verteilung analysiert, um sozioökonomische Störfaktoren zu untersuchen.
Die Variablen Alter, Geschlecht und Verweildauer sowie die häufigsten allgemeinen ICD-10-, OPS- und HNO-spezifischen OPS-Kodes zeigten auf Basis der klinischen Relevanz eine hohe Übereinstimmung. Bei den HNO-spezifischen ICD-10-Kodes wiesen zwei von elf der häufigsten Kodes eine maximale Abweichung von 3,71 % auf. Die Analyse sozioökonomischer Faktoren und der regionalen Verteilung ergab keine Hinweise auf relevante Abweichungen.
Großes Potenzial für die Forschung
Dr. Mehdi Dastur, Abteilungsleitung Medizin Tiplu GmbH: „Die sehr hohe Übereinstimmung der untersuchten Variablen weist auf die Repräsentativität des ML-Datensatzes im Vergleich zu den DESTATIS-Daten hin. Dieses Ergebnis ebnet den Weg für zukünftige epidemiologische Studien auf Basis weiterer Variablen, insbesondere aus Labor- und Messwerten sowie aus der schriftlichen Dokumentation, die der Forschung bislang nicht zur Verfügung standen.”
Die vollständige Studie ist auf PLOS One verfügbar.